Document Classifier
The TransformersDocumentClassifier Node is a transformer based classification model used to create predictions that can be attached to retrieved documents as metadata. For example, by using a sentiment model, you can label each document as being either positive or negative in sentiment. Through a tight integration with the HuggingFace model hub, you can easily load any classification model by simply supplying the model name.
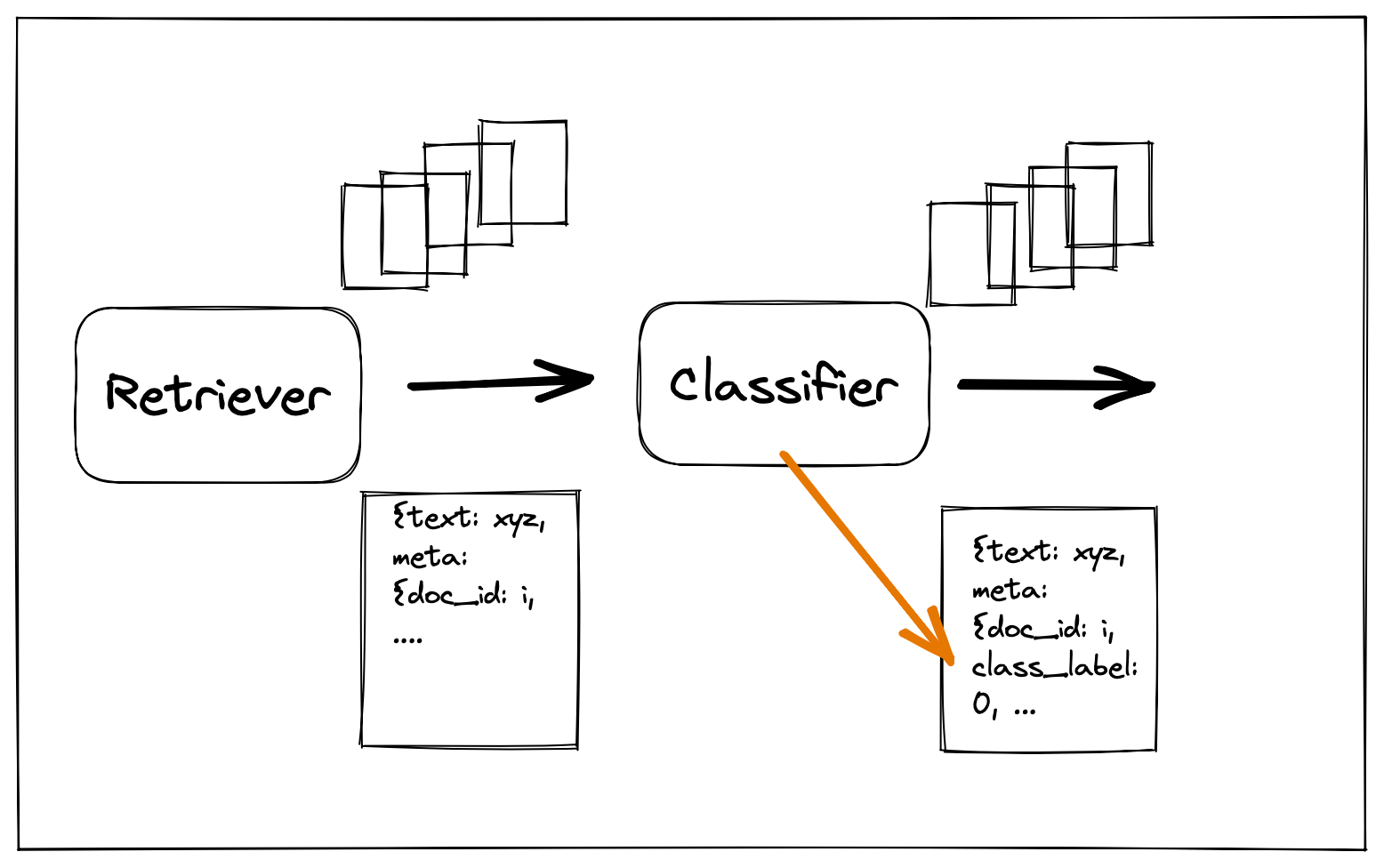
Note that the Document Classifier is different from the Query Classifier. While the Query Classifier categorizes incoming queries in order to route them to different parts of the pipeline, the Document Classifier is used to create classification labels that can be attached to retrieved documents as metadata.
Usage
Initialize it as follows:
from haystack.document_classifier import TransformersDocumentClassifier
doc_classifier_model = 'bhadresh-savani/distilbert-base-uncased-emotion'doc_classifier = TransformersDocumentClassifier(model_name_or_path=doc_classifier_model)
Alternatively, if you can't find a classification model that has been pre-trained for your exact classification task, you can use zero-shot classification with a custom list of labels and a Natural language Inference (NLI) model as follows:
doc_classifier_model = 'cross-encoder/nli-distilroberta-base'doc_classifier = TransformersDocumentClassifier( model_name_or_path=doc_classifier_model, task="zero-shot-classification", labels=["negative", "positive"]
It is slotted into a pipeline as follows:
pipeline = Pipeline()pipeline.add_node(component=retriever, name="Retriever", inputs=["Query"])pipeline.add_node(component=doc_classifier, name='DocClassifier', inputs=['Retriever'])
It can also be run in isolation:
documents = doc_classifier.predict( documents = [doc1, doc2, doc3, ...]):